jueves, 30 de abril de 2015
Actividad #16
Estrategias de procesamiento de consultas distribuidas.
Consulta distribuida:· Las consultas distribuidas tienen acceso a datos de varios orígenes de datos heterogéneos.
· Estos orígenes de datos pueden estar almacenado en el mismo equipo o en equipos diferentes.
· El procesamiento de consultas tiene varias etapas a seguir para resolver una consulta en sql.
· Las características del modelo relacional permiten que cada motor de base de datos elija su propia representación: álgebra relacional.
Existen varios medios para calcular la respuesta a una consulta.
Es preciso tener en cuenta otros factores como son:
· El costo de transmisión de datos en la red.
· Repetición y fragmentación.
· Procesamiento de intersección simple.
Árboles de consultas:
Son estructuras de datos en forma de árbol, en donde, los datos al estar ordenados en la estructura, hace más ágiles las consultas.
Pasos:
– Parsing y traducción de la consulta
– Optimización
– Generación de código
– Ejecución de la consulta
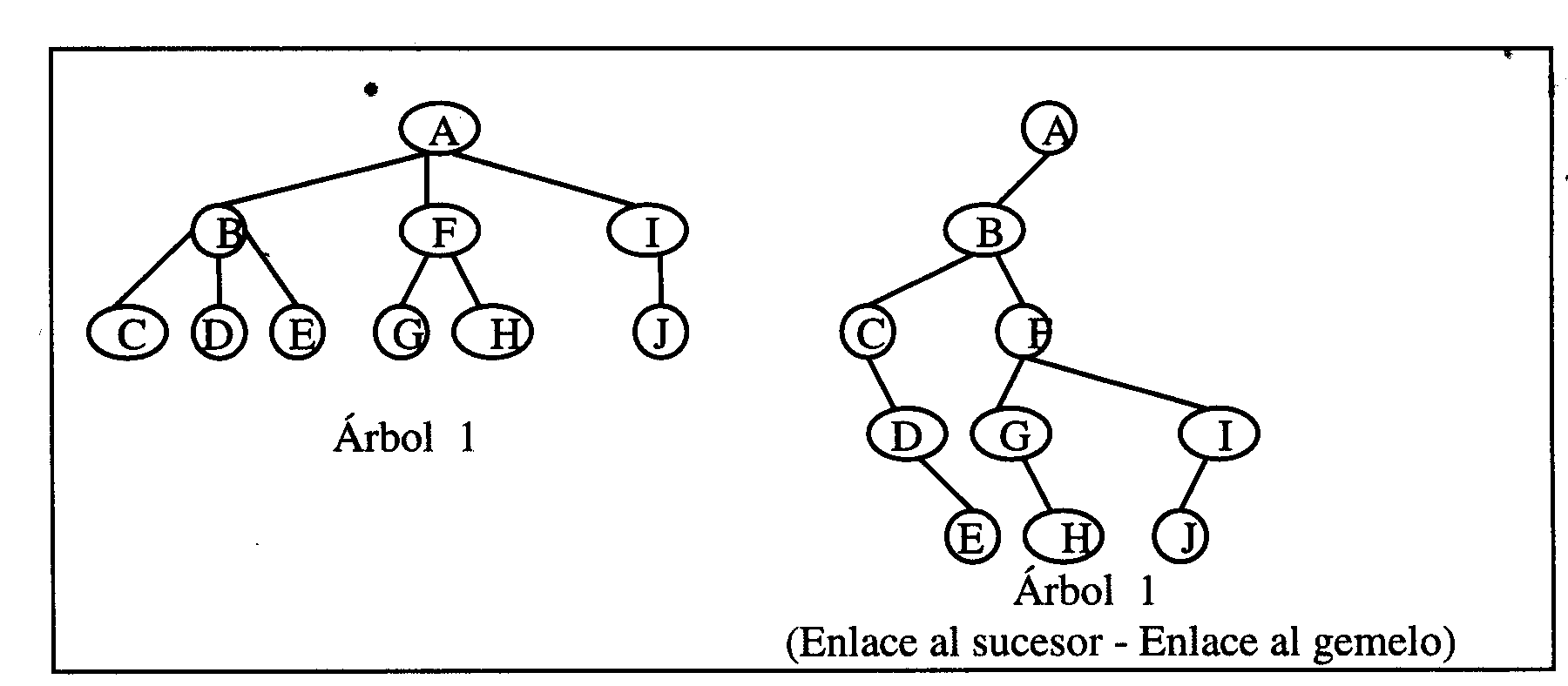
Transformaciones equivalentes.
Cuando una base de datos se encuentra en múltiples servidores y distribuye a un número determinado de nodos tenemos:
El servidor recibe una petición de un nodo.
El servidor es atacado por el acceso concurrente a la base de datos cargada localmente.
El servidor muestra un resultado y le da un hilo a cada una de las maquinas nodo de la red local.
Métodos de ejecución del join.
Existen diferentes algoritmos que pueden obtener transformaciones eficientes en el procesamiento de consultas:
Join externo.
Un outer join es una extensión del operador join que se utiliza a menudo para trabajar con la información que falta.Join complejos.
Los join en bucle anidado y en bucle anidado por bloques son útiles siempre, sin embargo, las otras técnicas de join son más eficientes que estas, pero sólo se pueden utilizar en condiciones particulares tales como join natural o equi-join.Join por asociación híbrida.
El algoritmo de join por asociación híbrida realiza otra optimización; es útil cuando el tamaño de la memoria es relativamente grande paro aún así, no cabe toda la relación s en memoria.Join por asociación.
Al igual que el algoritmo de join por mezcla, el algoritmo de join por asociación se puede utilizar para un Join natural o un equi-join. Este algoritmo utiliza una función de asociación h para dividir las tuplas de ambas relaciones.Join por mezcla.
Este algoritmo se puede utilizar para calcular si un Join natural es óptimo en la búsqueda o consulta.Join en bucles anidados por bloques.
Una variante del algoritmo anterior puede lograr un ahorro en el acceso a bloques, si se procesan las relaciones por bloques en vez de por tuplas.
Puntos para la optimización de las consultas distribuidas.
•Identificar sentencias problemáticas•Verificar las estadísticas
•Revisar los planes de ejecución
•Reestructurar las sentencias SQL
•Reestructurar los índices
•Mantener los planes de ejecución
Para optimizar el uso de la memoria compartida:
- Escribir código genérico „
- Seguir estándares de codificación „
- Usar variables a reemplazar en tiempo de ejecución
Optimización de consulta
Es el proceso de selección del plan de evaluación de las consultas más eficientes de entre las muchas estrategias generalmente disponibles para el procesamiento de una consulta dada, especialmente si la consulta es compleja.Es el proceso de selección del plan de evaluación de las consultas más eficiente entre las estrategias disponibles para el procesamiento de una consulta dada.
A través del álgebra relacional intenta hallar una expresión equivalente a la expresión dada ƒ.
Elección de una estrategia detallada para el procesamiento de la consulta:
o Selección del algoritmo que se usará para ejecutar una operación
o Selección de los índices concretos que se van a emplear
Importancia
Crear un plan de evaluación de consultas que minimice el costo de la evaluación de consultas a través de la optimación de la misma.
Optimización global
El compilador de SQL funciona en tres fases, que ayuda a producir una estrategia de acceso óptima para evaluar una consulta que hace referencia a una fuente de datos remota. Estas fases son análisis de envío, optimización global y generación de SQL remoto.El objetivo de la optimización global es producir un plan de acceso que optimiza las operaciones de consulta en todas las fuentes de datos globalmente, en todo el sistema federado. Un plan de acceso que es óptimo globalmente tiene como mínimo un coste global de ejecución en una sistema federado. la fase de generación de SQL remoto convierte a la inversa el plan optimo globalmente en fragmentos de consulta que se ejecutan como fuentes de datos individuales.
Dada una consulta algebraica sobre fragmentos, el objetivo de esta capa es hallar una estrategia de ejecución para la consulta cercana a la óptima. La estrategia de ejecución para una consulta distribuida puede ser descrita con los operadores del álgebra relacional y con primitivas de comunicación para transferir datos entre nodos. Para encontrar una buena transformación se consideran las características de los fragmentos, tales como, sus cordialidades. Un aspecto importante de la optimización de consultas es el ordenamiento de juntas, dado que algunas permutaciones de juntas dentro de la consulta pueden conducir a un mejoramiento de varios órdenes de magnitud. La salida de la capa de optimización global es una consulta algebraica optimizada con operación de comunicación incluida sobre los fragmentos.
Optimización Local de Consultas
El trabajo de la última capa se efectúa en todos los nodos con fragmentos involucrados en la consulta. Cada subconsulta que se ejecuta en un nodo, llamada consulta local, es optimizada usando el esquema local del nodo. Hasta este momento, se pueden eligen los algoritmos para realizar las operaciones relacionales.viernes, 24 de abril de 2015
Actividad 15
Optimización de
consulta
Es
el proceso de selección del plan de evaluación de las consultas más eficientes
de entre las muchas estrategias generalmente disponibles para el procesamiento
de una consulta dada, especialmente si la consulta es compleja.
Es el proceso de selección del plan de evaluación de las consultas más eficiente entre las estrategias disponibles para el procesamiento de una consulta dada.
Es el proceso de selección del plan de evaluación de las consultas más eficiente entre las estrategias disponibles para el procesamiento de una consulta dada.
A
través del álgebra relacional intenta hallar una expresión equivalente a la
expresión dada ƒ.
Elección
de una estrategia detallada para el procesamiento de la consulta:
o
Selección
del algoritmo que se usará para ejecutar una operación
o Selección de los índices
concretos que se van a emplear
Importancia
Crear
un plan de evaluación de consultas que minimice el costo de la evaluación de
consultas a través de la optimación de la misma.
Optimización
global
El
compilador de SQL funciona en tres fases, que ayuda a producir una
estrategia de acceso óptima para evaluar una consulta que hace referencia a una
fuente de datos remota. Estas fases son análisis de envío, optimización global
y generación de SQL remoto.
El
objetivo de la optimización global es producir un plan de acceso que optimiza
las operaciones de consulta en todas las fuentes de datos globalmente, en todo
el sistema federado. Un plan de acceso que es óptimo globalmente tiene como mínimo
un coste global de ejecución en una sistema federado. la fase de generación de
SQL remoto convierte a la inversa el plan optimo globalmente en fragmentos de
consulta que se ejecutan como fuentes de datos individuales.
Dada una consulta algebraica sobre fragmentos, el objetivo de esta capa es hallar una estrategia de ejecución para la consulta cercana a la óptima. La estrategia de ejecución para una consulta distribuida puede ser descrita con los operadores del álgebra relacional y con primitivas de comunicación para transferir datos entre nodos. Para encontrar una buena transformación se consideran las características de los fragmentos, tales como, sus cordialidades. Un aspecto importante de la optimización de consultas es el ordenamiento de juntas, dado que algunas permutaciones de juntas dentro de la consulta pueden conducir a un mejoramiento de varios órdenes de magnitud. La salida de la capa de optimización global es una consulta algebraica optimizada con operación de comunicación incluida sobre los fragmentos.
Dada una consulta algebraica sobre fragmentos, el objetivo de esta capa es hallar una estrategia de ejecución para la consulta cercana a la óptima. La estrategia de ejecución para una consulta distribuida puede ser descrita con los operadores del álgebra relacional y con primitivas de comunicación para transferir datos entre nodos. Para encontrar una buena transformación se consideran las características de los fragmentos, tales como, sus cordialidades. Un aspecto importante de la optimización de consultas es el ordenamiento de juntas, dado que algunas permutaciones de juntas dentro de la consulta pueden conducir a un mejoramiento de varios órdenes de magnitud. La salida de la capa de optimización global es una consulta algebraica optimizada con operación de comunicación incluida sobre los fragmentos.
Optimización
Local de Consultas
El
trabajo de la última capa se efectúa en todos los nodos con fragmentos
involucrados en la consulta. Cada subconsulta que se ejecuta en un nodo,
llamada consulta local, es optimizada usando el esquema local del nodo. Hasta
este momento, se pueden eligen los algoritmos para realizar las operaciones
relacionales.
lunes, 20 de abril de 2015
Actividad 15.
Estrategias de procesamiento de
consultas distribuidas.
Consulta
distribuida:
·
Las
consultas distribuidas tienen acceso a datos de varios orígenes de datos
heterogéneos.
·
Estos orígenes
de datos pueden estar almacenado en el mismo equipo o en equipos diferentes.
·
El procesamiento
de consultas tiene varias etapas a seguir para resolver una consulta en sql.
·
Las características
del modelo relacional permiten que cada motor de base de datos elija su propia
representación: álgebra relacional.
Existen varios
medios para calcular la respuesta a una consulta.
Es preciso tener en
cuenta otros factores como son:
·
El costo de
transmisión de datos en la red.
·
Repetición y
fragmentación.
·
Procesamiento
de intersección simple.
Árboles de consultas:
Son estructuras de
datos en forma de árbol, en donde, los datos al estar ordenados en la
estructura, hace más ágiles las consultas.
Pasos:
– Parsing y
traducción de la consulta
– Optimización
– Generación de código
– Ejecución de la consulta
Transformaciones
equivalentes.
Cuando
una base de datos se encuentra en múltiples servidores y distribuye a un número
determinado de nodos tenemos:
El
servidor recibe una petición de un nodo.
El
servidor es atacado por el acceso concurrente a la base de datos cargada
localmente.
El
servidor muestra un resultado y le da un hilo a cada una de las maquinas nodo
de la red local.
Métodos
de ejecución del join.
Existen
diferentes algoritmos que pueden obtener transformaciones eficientes en el
procesamiento de consultas:
- Join externo.
Un
outer join es una extensión del operador join que se utiliza a menudo para
trabajar con la información que falta.
- Join complejos.
Los
join en bucle anidado y en bucle anidado por bloques son útiles siempre, sin
embargo, las otras técnicas de join son más eficientes que estas, pero sólo se
pueden utilizar en condiciones particulares tales como join natural o
equi-join.
- Join por asociación híbrida.
El
algoritmo de join por asociación híbrida realiza otra optimización; es útil
cuando el tamaño de la memoria es relativamente grande paro aún así, no cabe
toda la relación s en memoria.
- Join por asociación.
Al
igual que el algoritmo de join por mezcla, el algoritmo de join por asociación
se puede utilizar para un Join natural o un equi-join. Este algoritmo utiliza
una función de asociación h para dividir las tuplas de ambas relaciones.
- Join por mezcla.
Este
algoritmo se puede utilizar para calcular si un Join natural es óptimo en la
búsqueda o consulta.
- Join en bucles anidados por bloques.
Una
variante del algoritmo anterior puede lograr un ahorro en el acceso a bloques,
si se procesan las relaciones por bloques en vez de por tuplas.
martes, 14 de abril de 2015










Suscribirse a:
Entradas (Atom)